Churn Prediction Inference - Batch or serverless real-time
With AutoML, our best model was automatically saved in our MLFlow registry.
All we need to do now is use this model to run Inferences. A simple solution is to share the model name to our Data Engineering team and they'll be able to call this model within the pipeline they maintained. That's what we did in our Delta Live Table pipeline!
Alternatively, this can be schedule in a separate job. Here is an example to show you how MLFlow can be directly used to retriver the model and run inferences.

Deploying the model for batch inferences

Now that our model is available in the Registry, we can load it to compute our inferences and save them in a table to start building dashboards.
We will use MLFlow function to load a pyspark UDF and distribute our inference in the entire cluster. If the data is small, we can also load the model with plain python and use a pandas Dataframe.
If you don't know how to start, Databricks can generate a batch inference notebook in just one click from the model registry: Open MLFlow model registry and click the "User model for inference" button!
Scaling inferences using Spark
We'll first see how it can be loaded as a spark UDF and called directly in a SQL function:
Pure pandas inference
If we have a small dataset, we can also compute our segment using a single node and pandas API:
Realtime model serving with Databricks serverless serving

Databricks also provides serverless serving.
Click on model Serving, enable realtime serverless and your endpoint will be created, providing serving over REST api within a Click.
Databricks Serverless offer autoscaling, including downscaling to zero when you don't have any traffic to offer best-in-class TCO while keeping low-latencies model serving.
To deploy your serverless model, open the [Model Serving menu](https://xxxx.cloud.databricks.com/?o=1660015457675682
mlflow/endpoints), and select the model you registered within Unity Catalog.
Next step: Leverage inferences and automate actions to increase revenueAutomate action to reduce churn based on predictions
We now have an end 2 end data pipeline analizing and predicting churn. We can now easily trigger actions to reduce the churn based on our business:
- Send targeting email campaign to the customer the most likely to churn
- Phone campaign to discuss with our customers and understand what's going
- Understand what's wrong with our line of product and fixing it
These actions are out of the scope of this demo and simply leverage the Churn prediction field from our ML model.
Track churn impact over the next month and campaign impact
Of course, this churn prediction can be re-used in our dashboard to analyse future churn and measure churn reduction.
The pipeline created with the Lakehouse will offer a strong ROI: it took us a few hours to setup this pipeline end 2 end and we have potential gain for $129,914 / month!
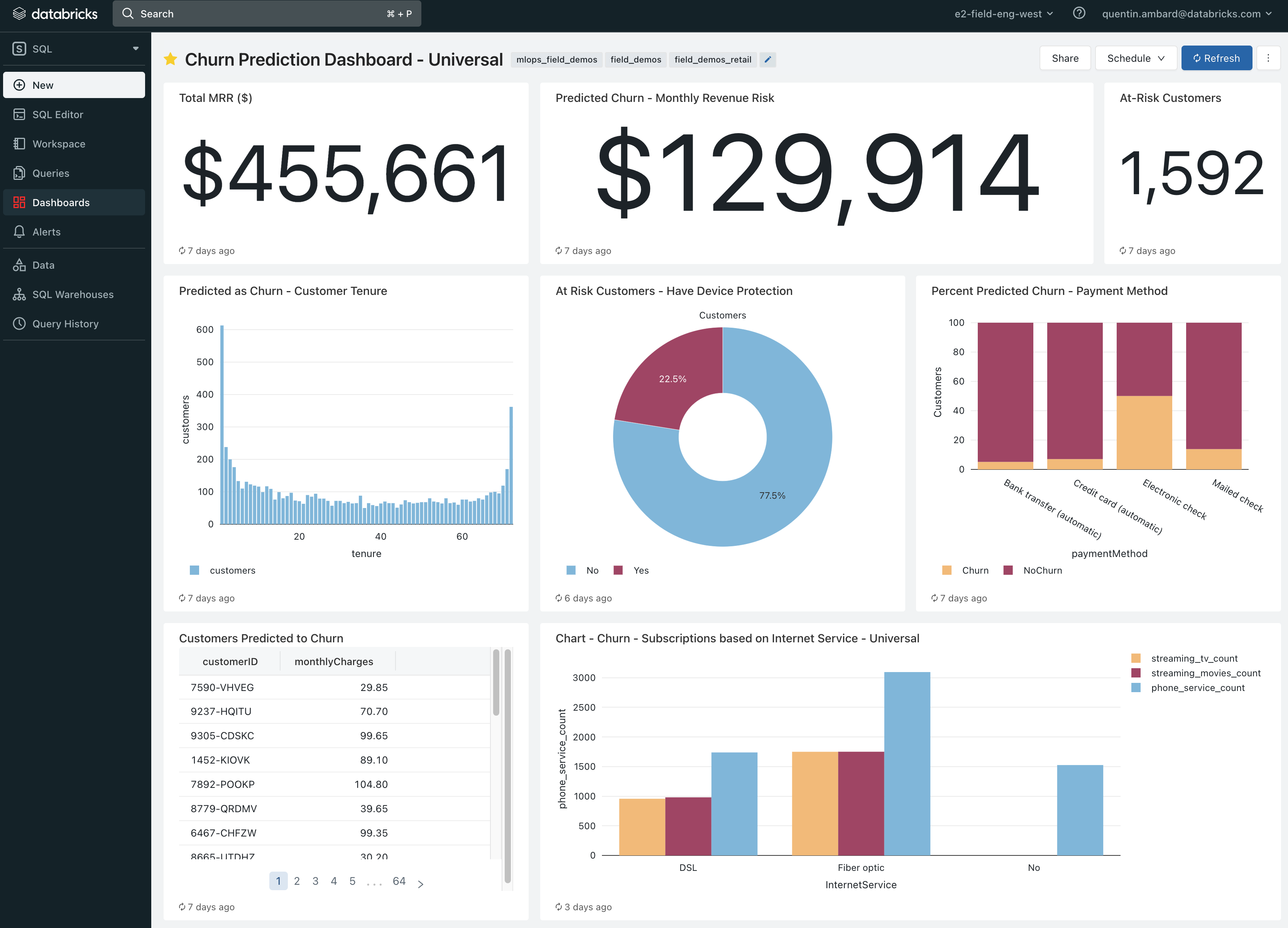
Open the Churn prediction DBSQL dashboard
Reducing churn leveraging Databricks GenAI and LLMs capabilities
GenAI provides unique capabilities to improve your customer relationship, providing better services but also better analyzing your churn risk.
Databricks provides built-in GenAI capabilities for you to accelerate such GenAI apps deployment.
Discover how with the [04.4-GenAI-for-churn]($./04.4-GenAI-for-churn) Notebook.
[Go back to the introduction]($../00-churn-introduction-lakehouse)